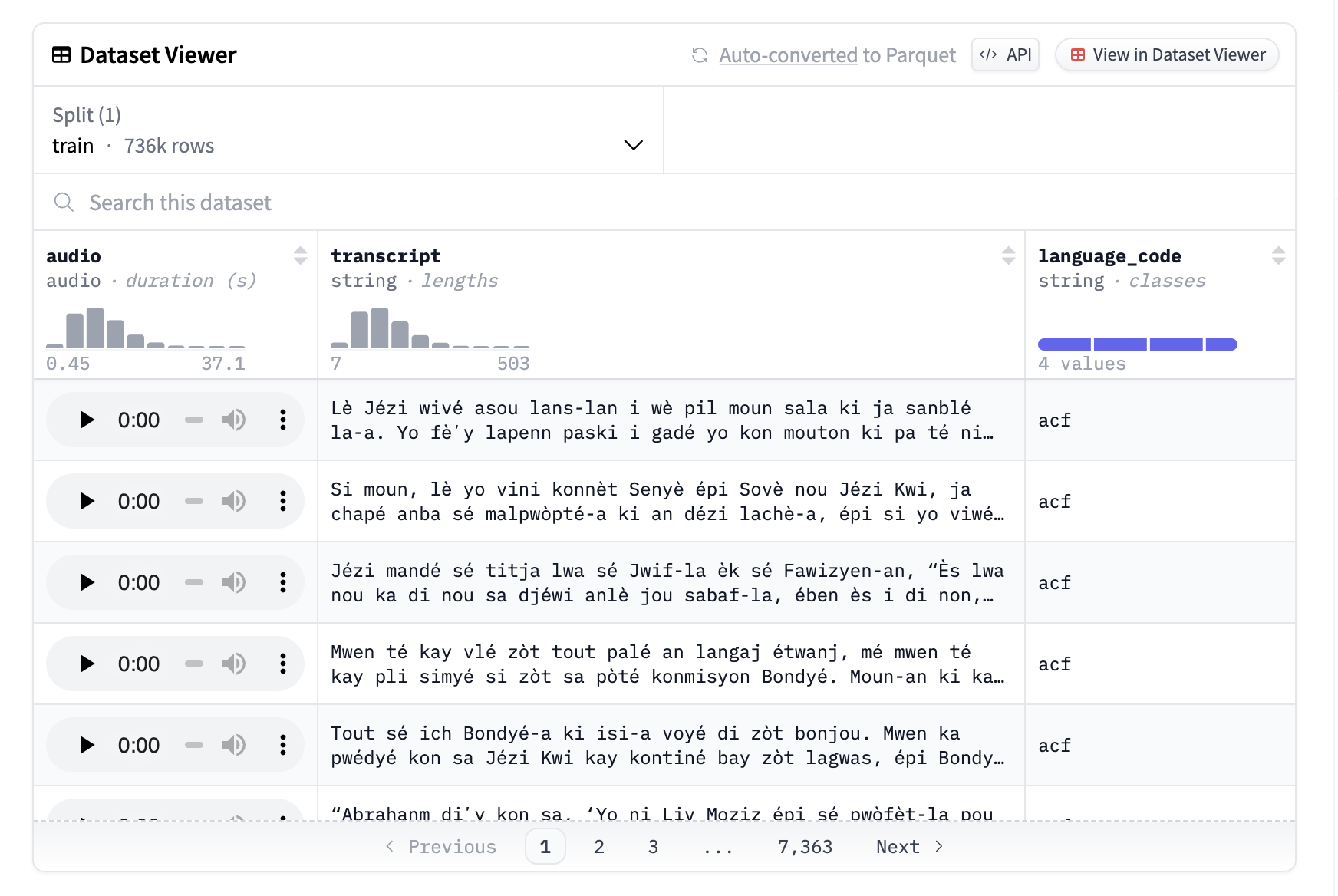
In recent research, the Institute for Natural Language Processing (IMS) at the University of Stuttgart, Germany, has introduced ToucanTTS, significantly advancing the field of text-to-speech (TTS) technology. With support for speech synthesis in more than 7,000 languages, this new toolset is capable of completely transforming the field of multilingual TTS systems.
ToucanTTS is an advanced TTS toolbox using which modern speech synthesis models can be taught, trained, and used. Since PyTorch and Python are the only programming languages used in its development, it is highly functional and performant yet approachable and suitable for beginners. The toolkit stands out especially for its broad language support, which caters to the needs of a wide range of international audiences.
ToucanTTS is the most multilingual TTS model available, distinguished by its capacity to synthesize speech in over 7,000 languages. It facilitates multi-speaker voice synthesis, which lets users mimic the rhythm, stress, and intonation of several speakers. This functionality is especially useful for applications that demand stylistic diversity and voice customization.
Human-in-the-loop editing functionality has been included in the toolkit, which is particularly useful for literary studies and poetry reading assignments. With the use of this feature, users can customize the synthesized speech to suit their own requirements and tastes. Interactive demonstrations have been offered by ToucanTTS for a range of applications, such as voice design, style cloning, multilingual speech synthesis, and human-edited poetry reading. These examples show off the toolkit’s versatility and robustness, which expedites users’ understanding and utilization of its capabilities.
ToucanTTS has been built on the FastSpeech 2 architecture at its core, with certain improvements, including a PortaSpeech-inspired normalizing flow-based PostNet. This design guarantees natural-sounding, high-quality speech synthesis. A self-contained aligner trained with Connectionist Temporal Classification (CTC) and spectrogram reconstruction has also been included in the toolkit for various uses.
Using articulatory representations of phonemes as input is one of the most unique features of ToucanTTS. This method greatly improves the quality and usability of speech synthesis for low-resource languages by enabling the system to take advantage of multilingual data.
In conclusion, ToucanTTS is a notable development in text-to-speech technology. Its user-friendly design and wide range of language support make it highly beneficial for educators, researchers, and developers. ToucanTTS’s features and open-source nature guarantee that it will be essential in advancing and democratizing speech synthesis technology.
Check out the Dataset, GitHub, and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Toucan TTS: An MIT Licensed Text-to-Speech Advanced Toolbox with Speech Synthesis in More Than 7000 Languages appeared first on MarkTechPost.