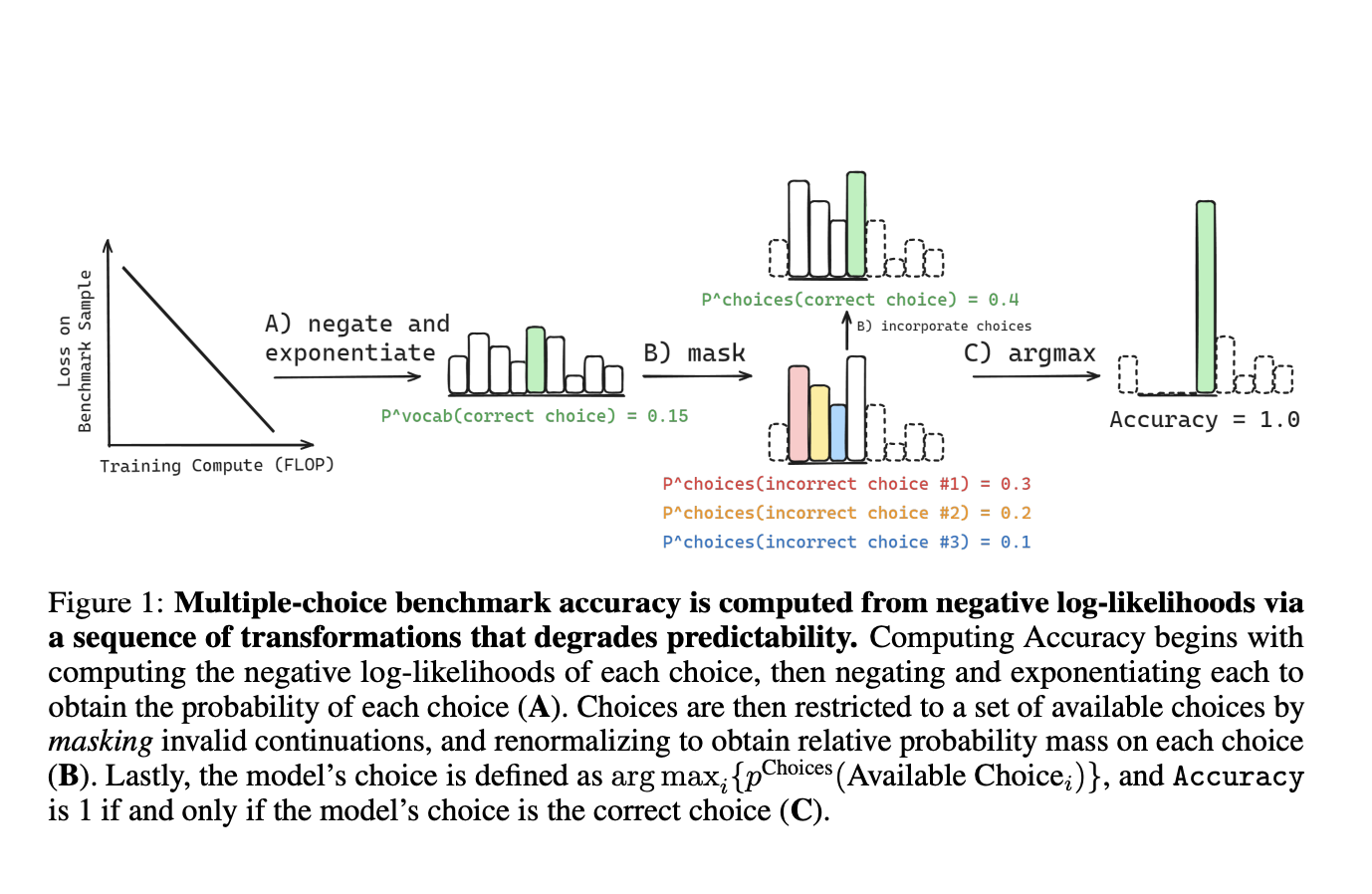
Predicting the scaling behavior of frontier AI systems like GPT-4, Claude, and Gemini is essential for understanding their potential and making decisions about their development and use. However, it is difficult to predict how these systems will perform on specific tasks as they scale up, despite the well-established relation between parameters, data, compute, and pretraining loss defined by the scaling laws. For example, performance on standard NLP benchmarks can sometimes show unpredictable changes with scale. Some studies suggest these unpredictable changes might be due to choices of metrics and lack of resolution.
This paper contains two main directions. The first is “Beyond Multiple Choice Benchmarks”, where the study focuses on benchmarks evaluated using loglikelihood-based multiple-choice formats. While this focus is valuable due to the usefulness and prevalence of such tasks, it limits the broader application of the findings. The second direction is “Predicting Benchmark Performance A Priori”, which explains why multiple-choice benchmark performance is difficult to predict using metrics like Accuracy and Brier Score. However, the analyses assume access to the scores of entire model families across various orders of magnitude of pretraining FLOPs and do not utilize backtesting.
Researchers from the University of Cambridge, Stanford CS, EleutherAI, and MILA have shown that common multiple-choice metrics, such as Accuracy, Brier Score, and Probability Correct, can be evaluated from raw model outputs. This is achieved through a sequence of transformations that gradually degrades the statistical relationship between these metrics and the scaling parameters. The main reason is that these metrics depend on a direct comparison between the correct output and a limited set of specific incorrect outputs. Therefore, accurately predicting downstream performance needs modeling how the probability mass fluctuates among particular incorrect alternatives.
Researchers worked on how probability mass on incorrect choices fluctuates with increasing compute. This helps in understanding why individual downstream metrics can be unpredictable, while pretraining loss scaling laws are more consistent since they don’t depend on specific incorrect choices. To design evaluations that effectively track the progress of advanced AI capabilities, it’s important to understand what affects downstream performance. Moreover, to see how the downstream capabilities on specific tasks change with scale for different model families, per-sample scores are generated from various model families and multiple-choice NLP benchmarks.
To accurately predict performance on multiple-choice question-answering tests, it’s important to understand how the probability of choosing the correct answer changes with scale as well as how the probability of choosing the wrong answer changes with scale. For metrics such as Accuracy, these predictions need to be made for each question because knowing the average probability of choosing wrong answers across many questions doesn’t specify the probability of choosing a specific wrong answer for a particular question. It is especially important to look at how the probabilities of choosing the correct and incorrect answers change together as more computational power is used.
In conclusion, researchers have found a factor that causes unpredictability in multiple-choice tests for frontier AI models. This factor is the probability of choosing incorrect answers. The results can influence to design the of future evaluations for frontier AI models that are reliably predictable with scaling. Future work focuses on creating more predictable evaluations for AI systems, particularly for complex and important capabilities. The researchers gave several future directions for extending the work and adopting their framework to further improve scaling-predictable evaluations.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post How Scale Impacts Predicting Downstream Capabilities of Frontier AI Models: Understanding the Elusiveness appeared first on MarkTechPost.