The efficient deployment of large language models (LLMs) necessitates high throughput and low latency. However, LLMs’ substantial memory consumption, particularly by the key-value (KV) cache, hinders achieving large batch sizes and high throughput. The KV cache, storing keys and values during generation, consumes over 30% of GPU memory. Various approaches such as compressing KV sequences and dynamic cache eviction policies, aim to alleviate this memory burden in LLMs.
While most works concentrate on compressing KV sequences, vLLM introduces paged attention to mitigate memory fragmentation. Various approaches include compressing prompts, removing input context redundancy, and incrementally compressing token spans. Other methods involve pruning unimportant tokens, applying different pruning strategies to attention heads, and storing only crucial tokens.
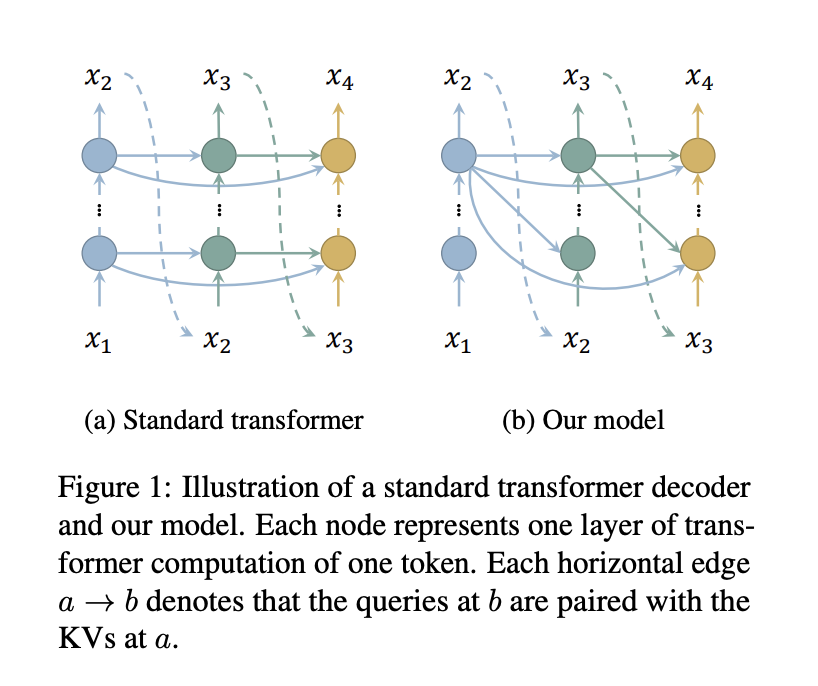
Researchers from the School of Information Science and Technology, ShanghaiTech University, and Shanghai Engineering Research Center of Intelligent Vision and Imaging present an efficient approach to reduce memory consumption in the KV cache of transformer decoders by decreasing the number of cached layers. By pairing queries of all layers with keys and values of just the top layer, only one layer’s keys and values need to be cached, significantly saving memory without additional computation overhead. Inspired by the iterative improvement process of token representation, the model attends only to the top layer, akin to cross-attention in standard transformers. The model integrates standard attention for a few layers to mitigate performance degradation.
The proposed method pairs queries of all layers with keys and values of only the top layer, eliminating the need to cache or compute KVs for other layers, thereby saving memory and computation. This also reduces model parameters by eliminating the need for weights mapping hidden representations to KVs for those layers. To address the cyclic dependency problem caused by each token attending to itself, the model masks the diagonal of the attention matrix, using zero vectors as dummy KVs for the first token. Retaining standard attention for a few layers, termed warmup layers, maintains the syntactic-semantic pattern observed in transformers, ensuring competitive performance with standard models.
Researchers evaluated their method using models with 1.1B, 7B, and 30B parameters on different GPUs, including NVIDIA GeForce RTX 3090 and A100. The implementation utilizes HuggingFace Transformers with FlashAttention 2, fused RMS norm, fused cross-entropy, and fused SwiGLU. Evaluation measures include latency and throughput, with results indicating significantly larger batch sizes and higher throughput than standard Llama models across various settings. Also, zero-shot accuracy on commonsense reasoning tasks is comparable to TinyLlama. Integration with StreamingLLM demonstrates lower latency and memory consumption, with the ability to process infinite-length tokens effectively. The method achieves competitive performance and higher inference efficiency, although pre-training requires more time due to the iterative training process.
This study presents a robust method to reduce memory consumption and enhance throughput in LLMs by minimizing the number of layers requiring key and value computation and caching. Empirical results demonstrate substantial memory reduction and throughput improvement with minimal performance loss. Also, the method seamlessly integrates with other memory-saving techniques like StreamingLLM.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post An Efficient AI Approach to Memory Reduction and Throughput Enhancement in LLMs appeared first on MarkTechPost.