Transformers have taken the machine learning world by storm with their powerful self-attention mechanism, achieving state-of-the-art results in areas like natural language processing and computer vision. However, when it came to graph data, which is ubiquitous in domains such as social networks, biology, and chemistry, the classic Transformer models hit a major bottleneck due to their quadratic computational complexity scaling with the number of nodes in the graph.
Previous works attempted to tackle this problem by restricting the receptive field of nodes through techniques like sampling or applying linear attention approximations directly to graph Transformers. However, these approaches had inherent flaws – the sampling strategy sacrificed the key advantage of self-attention, which is the global receptive field. At the same time, the linear attention approximations were incompatible with the common relative structural encoding used in graph Transformers, significantly reducing the model’s ability to learn graph structures.
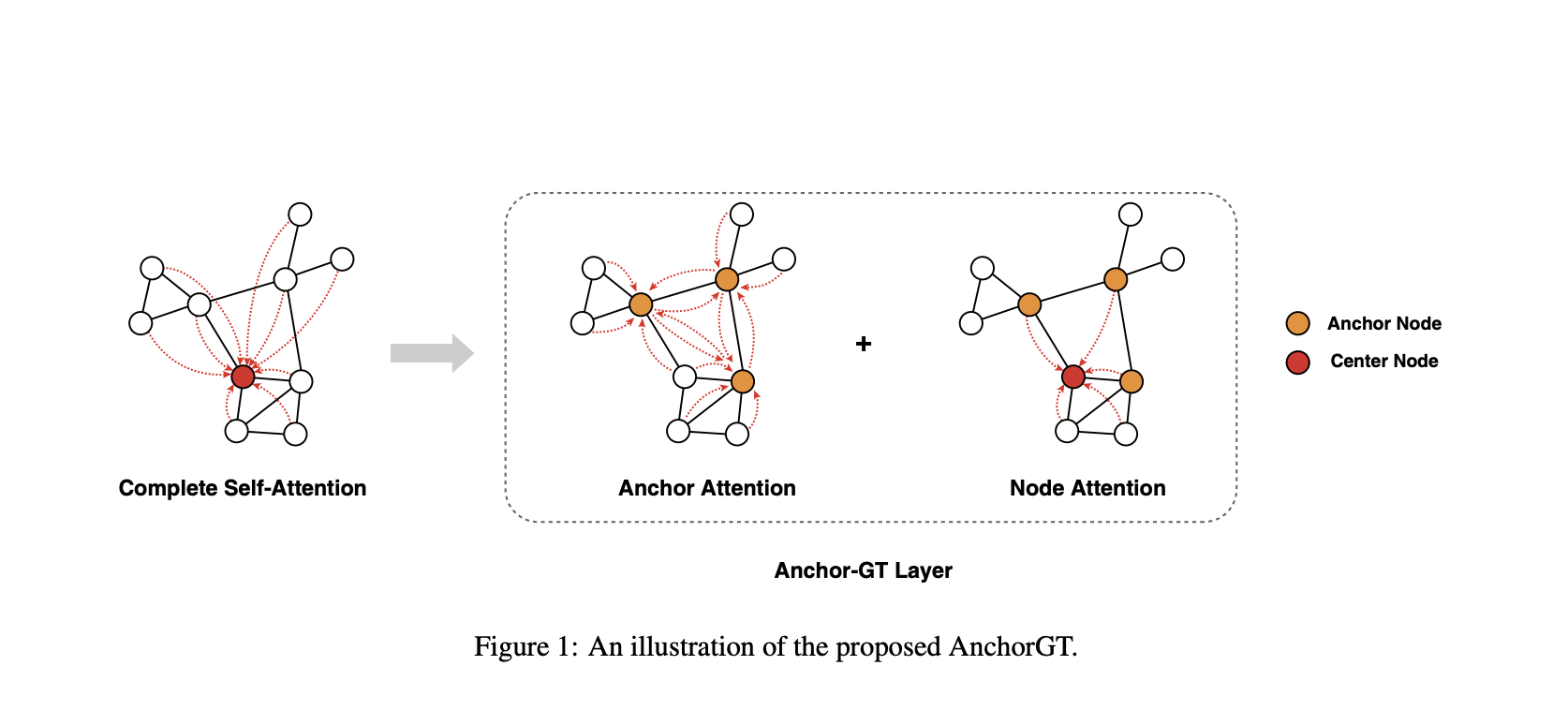
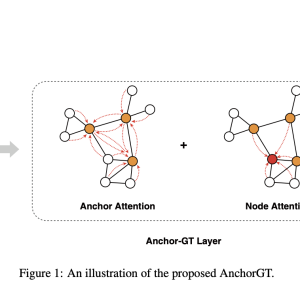
To address these limitations, a team of researchers proposed AnchorGT in this paper, which offers an elegant solution to the scalability challenge while preserving the expressive power of Transformers. The core idea behind AnchorGT is deceptively simple yet ingenious. Instead of allowing each node to attend to every other node (the default attention mechanism in Transformers), the researchers pick a small set of strategically chosen “anchor” nodes that act as information hubs. Now, each node only needs to attend to its local neighbors and these anchor nodes, significantly reducing the computational burden while still capturing global information.
The researchers leverage a concept from graph theory called the “k-dominating set” to select the anchor nodes. A k-dominating set is a subset of nodes such that every node in the graph is at most k hops away from at least one anchor node. This set can be computed efficiently using a greedy algorithm that iteratively selects high-degree nodes and removes their k-hop neighborhoods until all nodes are covered.
With the anchor set in place, the attention mechanism is redesigned such that each node attends to its k-hop neighbors and the anchor set. Specifically, for a node v, its representation hv is updated by attending to the representations of nodes in its receptive field R(v) = Nk(v) ∪ S, where Nk(v) is the k-hop neighborhood of v, and S is the anchor set. The attention scores are computed using a query-key-value paradigm, with the structural information between node pairs injected via relative structural encodings like shortest path distance.
The researchers theoretically prove that when using structural encodings satisfying certain conditions (like shortest path distance), AnchorGT is strictly more expressive than traditional graph neural networks based on the Weisfeiler-Lehman test, a powerful tool for analyzing the expressive power of graph representations.
In their experiments, the researchers evaluated AnchorGT variants of popular graph Transformer models like Graphormer and GraphGPS on various graph learning tasks, including graph-level regression on datasets like QM9 and node classification on Citeseer and Pubmed. Across these benchmarks, AnchorGT models matched or even exceeded the performance of their original counterparts while being significantly more memory-efficient and faster.
For instance, on the ogb-PCQM4Mv2 dataset for graph-level regression, Graphormer-AnchorGT outperforms the original Graphormer while using 60% less GPU memory during training. The researchers conducted experiments on synthetic Erdős-Rényi random graphs of varying sizes to illustrate the scalability advantages further. Here, AnchorGT exhibited near-linear memory scaling compared to the quadratic blowup of standard Transformers, reducing memory consumption by about 60% for larger graphs.
The success of AnchorGT lies in its ability to strike a balance between computational efficiency and expressive power. By leveraging the notion of anchor nodes and redesigning the attention mechanism, the researchers have made graph Transformers practical for large-scale graph data without compromising their core strengths. This work paves the way for more scalable and effective graph learning methods, enabling the application of Transformers to a wider range of domains involving graph-structured data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post AnchorGT: A Novel Attention Architecture for Graph Transformers as a Flexible Building Block to Improve the Scalability of a Wide Range of Graph Transformer Models appeared first on MarkTechPost.