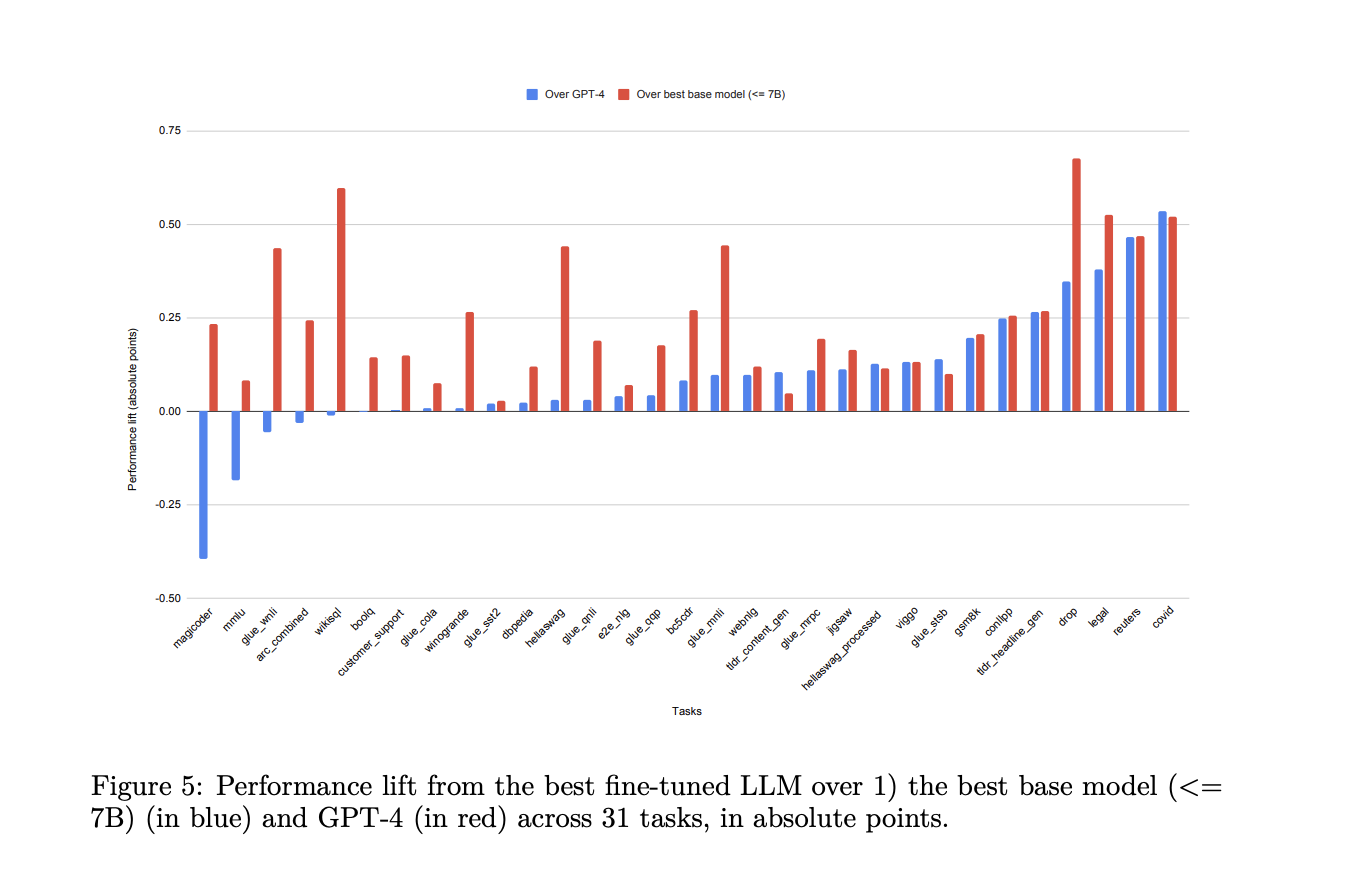
The natural language processing (NLP) field is continuously evolving, with large language models (LLMs) becoming integral to many applications. The push towards fine-tuning these models has become crucial to enhance their specific capabilities without requiring extensive computational resources. Researchers have recently explored ways to modify LLMs to ensure they perform optimally, even with limited computational resources. One key development is Low-Rank Adaptation (LoRA), a Parameter Efficient Fine-Tuning (PEFT) method that has shown promise in enhancing specialized models to outperform larger, more generalized ones. This method reduces the number of trainable parameters, lowers memory usage, and retains accuracy.
The challenge of fine-tuning is maintaining performance without excessive computational demand. The research team’s approach revolves around leveraging LoRA, which introduces low-rank matrices to existing layers of frozen model weights. This method allows specialized models to achieve performance levels akin to full fine-tuning without needing a high number of trainable parameters. LoRA has demonstrated its effectiveness across different tasks, allowing researchers to maximize efficiency.
Researchers from Predibase introduced LoRA Land, a comprehensive project that evaluates fine-tuned LLMs across various tasks. The research team used 10 base models and 31 tasks to fine-tune 310 models. The tasks included classic NLP, coding, knowledge-based reasoning, and math-based problems. This effort was supported by LoRAX, the open-source inference server designed specifically for serving multiple LoRA fine-tuned LLMs. The server enables the simultaneous use of multiple models by leveraging shared base weights and dynamic adapter loading, thus allowing numerous models to be deployed on a single GPU.
To validate the proposed methodology, the research team conducted experiments using LoRA with 4-bit quantization on the base models, achieving remarkable results. They found that LoRA-based fine-tuned models outperformed their base models significantly, with performance improvements averaging over 34 points. Some models even surpassed GPT-4 by 10 points on average across different tasks. The researchers meticulously standardized their testing framework, ensuring consistency in fine-tuning parameters and queries to provide a fair assessment across models. LoRAX’s deployment capabilities were thoroughly evaluated, highlighting its ability to efficiently manage multiple models concurrently. With features like dynamic adapter loading and tiered weight caching, it achieved high concurrency levels while maintaining minimal latency.
The project’s results revealed a substantial performance boost from fine-tuning, which consistently and significantly enhanced LLM performance. Across all 310 models, the fine-tuned versions surpassed their base counterparts, with 224 models exceeding the benchmark set by GPT-4. On average, fine-tuned models performed better than non-fine-tuned models by up to 51.2 points. This study showed that fine-tuning with LoRA can be exceptionally effective, particularly for specialized tasks where a smaller model can outperform even the largest models like GPT-4.
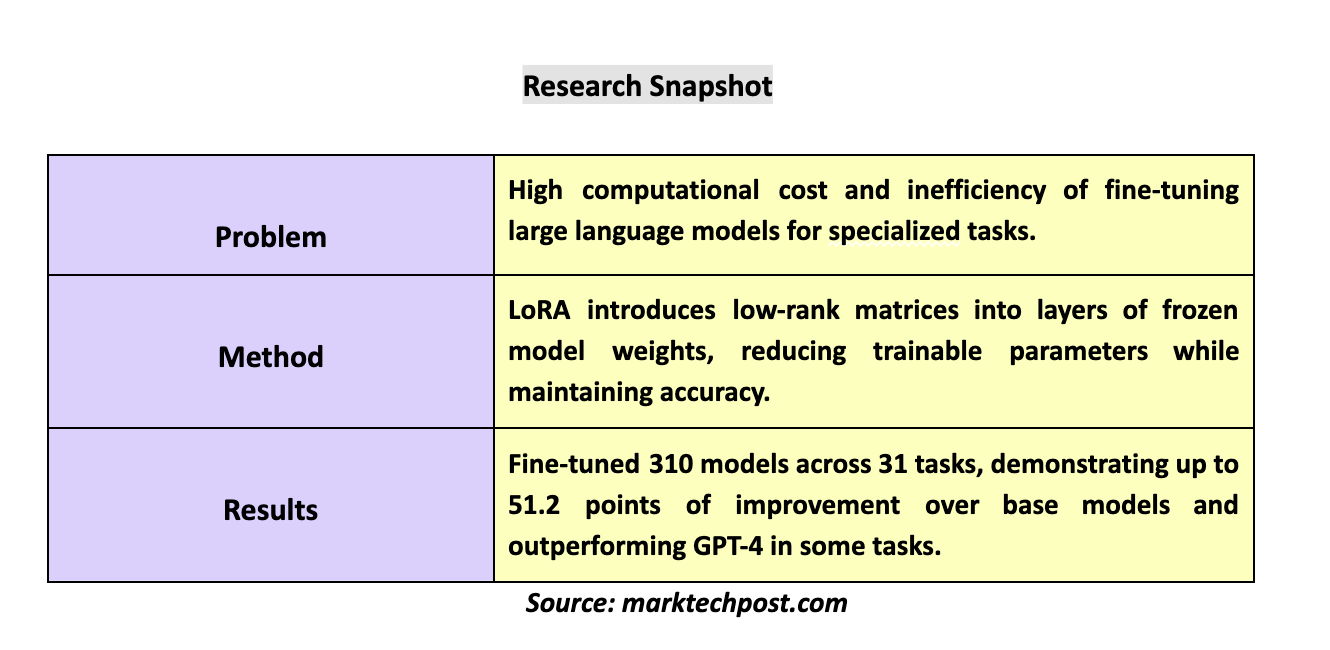
In conclusion, the LoRA Land project highlighted the effectiveness of LoRA in fine-tuning large language models, making them suitable for various specialized tasks. The study, covering 310 models fine-tuned across 31 tasks, demonstrated the efficiency and scalability of LoRA and its ability to match or surpass GPT-4’s performance in certain areas. LoRAX, the inference server used in this study, could handle many models simultaneously on a single GPU, underscoring the potential of efficiently deploying multiple fine-tuned models. The project emphasizes the advantages of specialized LLMs and the viability of LoRAX for future AI applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post Predibase Researchers Present a Technical Report of 310 Fine-tuned LLMs that Rival GPT-4 appeared first on MarkTechPost.