Long-context large language models (LLMs) have garnered attention, with extended training windows enabling processing of extensive context. However, recent studies highlight a challenge: these LLMs struggle to utilize middle information effectively, termed the lost-in-the-middle challenge. While the LLM can comprehend the information at the beginning and end of the long context, it often overlooks the information in the middle. This impedes tasks like Needle-in-the-Haystack and passkey retrieval. Consequently, a pressing research question arises: how can long-context LLMs fully utilize the information in the long context?
Recent research has significantly advanced the exploration of training large models with extended context windows, particularly in long-context LLMs. This development primarily encompasses two directions: data engineering and effective training methods. Data engineering involves balancing, arrangement, instruction, data collection, and quality measurement. Effective training methods focus on optimizing training processes through techniques such as position encoding, batching strategy, parameter-efficient training, and novel model architectures. Evaluations of long-context models are conducted through real-world benchmarks like NarrativeQA and probing tasks like Needle-in-the-Haystack and passkey retrieval, providing insights into long-context utilization across various lengths and positions.
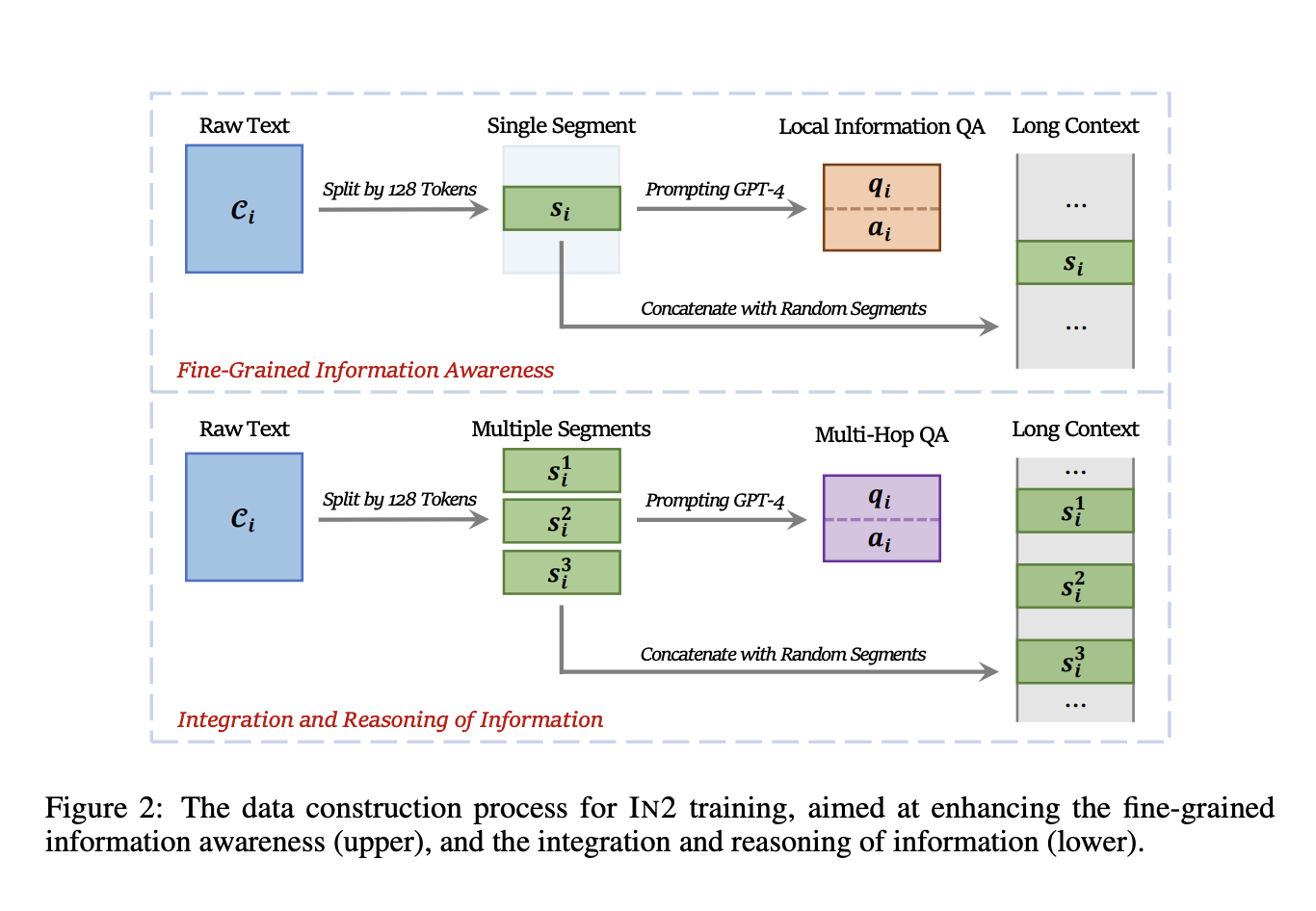
A team of researchers from IAIR, Xi’an Jiaotong University, Microsoft, and Peking University present INformation-INtensive (IN2) training to effectively utilize information throughout the context in long-context LLMs. IN2 training employs a purely data-driven approach using a synthesized long-context question-answer dataset. This dataset comprises concatenated long contexts from multiple short segments and corresponding question-answer pairs. These pairs prompt the model to recognize fine-grained information within individual segments and integrate information from various segments. The QA pairs are generated by directing GPT-4-Turbo with predefined instructions and raw segments.
IN2 training teaches the model that crucial information can exist throughout a long context, not just at its edges. The researchers construct a long-context question-answer training dataset, where answers require information from randomly placed short segments within the long context. Utilizing a natural language corpus, they generate question-answer pairs using a powerful LLM and synthesize long contexts containing relevant information from various texts. Two types of pairs are generated, focusing on fine-grained information awareness and integration of information across segments. They evenly distribute context lengths and retain some original short-context pairs to ensure balanced training. The resulting dataset comprises various types of data for different training purposes.
FILM-7B, trained using IN2 training, effectively addresses the lost-in-the-middle problem long-context models encounter. Probing results demonstrate FILM-7B’s robust performance compared to the vanilla Mistral model, indicating its ability to utilize information across different positions within the context. FILM-7B achieves performance comparable to or better than GPT-4-Turbo across various tasks. Quantitative analysis using average score and min-max gap metrics on VAL Probing further validates FILM-7B’s effectiveness, particularly in document and code probing tasks. These results suggest that open-source long-context models can rival proprietary ones, closing the performance gap
In conclusion, this research introduces IN2 training, representing a significant step forward in addressing the lost-in-the-middle challenge faced by long-context LLMs. By effectively utilizing information throughout the context, FILM-7B, trained using IN2, demonstrates robust performance across various tasks, comparable to or even outperforming proprietary models like GPT-4-Turbo. These findings underscore the potential of open-source models to bridge the gap with proprietary ones, paving the way for further advancements in long-context language modeling.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post From Lost to Found: INformation-INtensive (IN2) Training Revolutionizes Long-Context Language Understanding appeared first on MarkTechPost.