In computational linguistics, much research focuses on how language models handle and interpret extensive textual data. These models are crucial for tasks that require identifying and extracting specific information from large volumes of text, presenting a considerable challenge in ensuring accuracy and efficiency. A critical challenge in processing extensive text data is the model’s ability to accurately identify and extract relevant information from vast content pools. This issue is particularly pronounced in tasks where the model needs to discern specific details from large datasets or long documents.
Existing research includes models like LLaMA, Yi, QWen, and Mistral, which utilize advanced attention mechanisms to manage long-context information efficiently. Techniques such as continuous pretraining and sparse upcycling refine these models, enhancing their ability to navigate extensive texts. CopyNet and Induction Head have laid foundational work by integrating coping mechanisms and in-context learning into sequence-to-sequence models. Moreover, the Needle-in-a-Haystack test has been pivotal in benchmarking models’ precision in retrieving specific information within large datasets, shaping current strategies in language model development.
Researchers from Peking University, the University of Washington, MIT, UIUC, and the University of Edinburgh introduced “retrieval heads,” specialized attention mechanisms designed to enhance information retrieval in transformer-based language models. These heads selectively focus on crucial parts of extensive texts, a method distinguishing itself by focusing less on general attention across the entire dataset and more on targeted efficient data retrieval. This targeted approach is particularly effective in handling long-context scenarios, setting it apart from traditional models that often need help with large-scale data retrieval without specific optimizations.
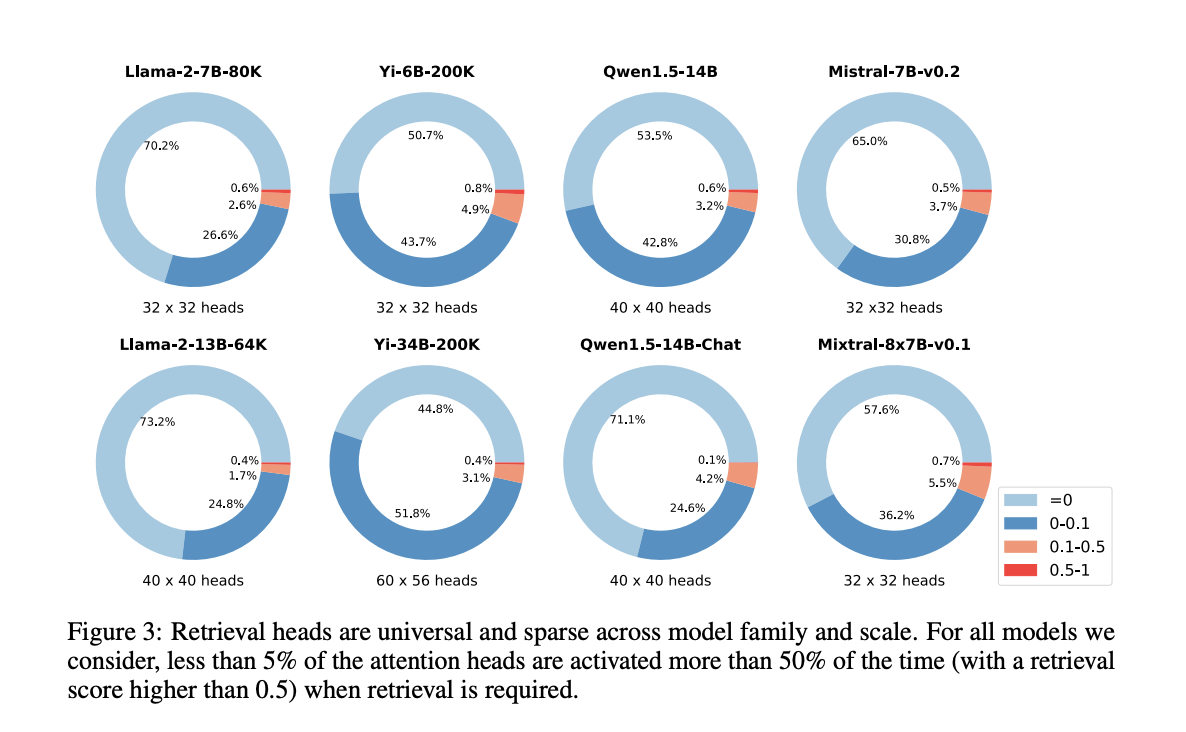
The methodology involved conducting detailed experiments across several prominent models such as LLaMA, Yi, QWen, and Mistral. Researchers applied the Needle-in-a-Haystack test, embedding specific pieces of information within large text blocks to measure the precision and effectiveness of retrieval heads. The study meticulously assessed the activation patterns of these heads under various experimental conditions, including different model scales and fine-tuning states, to determine their impact on performance and error rates. This systematic testing helped establish a quantitative basis for the significance of retrieval heads in improving accuracy and reducing hallucinations in language processing tasks.
The results revealed that models equipped with retrieval heads significantly outperformed those without in terms of accuracy and efficiency. The Needle-in-a-Haystack tests, accuracy dropped from 94.7% to 63.6% when top retrieval heads were masked. Moreover, models with active retrieval heads maintained high fidelity to input data, with error rates notably lower than models where these heads were deactivated. This empirical data underscores the effectiveness of retrieval heads in enhancing the precision and reliability of information retrieval within extensive text environments.
In conclusion, the research introduces and validates the concept of retrieval heads in transformer-based language models, demonstrating their pivotal role in enhancing information retrieval from extensive texts. The systematic testing across various models confirmed that retrieval heads significantly improve accuracy and reduce errors. This discovery deepens our understanding of attention mechanisms in large-scale text processing and suggests practical enhancements for developing more efficient and accurate language models, potentially benefiting a wide range of applications that rely on detailed and precise data extraction.
Check out the Paper and Github Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post This AI Paper Introduces a Novel Artificial Intelligence Approach in Precision Text Retrieval Using Retrieval Heads appeared first on MarkTechPost.